Real-time Replication of Database Tables to In-memory Cache of Application Servers
Summary
Relational databases have been the backbone of data processing in the financial services industry. With exponential growth in data and processing requirements in recent years, it is important that business applications can perform computations in a scalable manner. One of the approaches is to move the computations from SQL procedures hosted on a database server to a compute farm where microservices process data using in-memory replication of database tables. In this article, we will examine a technique of projecting relational database tables into in--memory cache of application server daemon processes.
Background
In a large scale database based application, performance issues were encountered in certain parts of the application that implemented compliance rules using stored procedures. The rules run in the critical part of the user triggered trade booking process where waiting time had to be minimized. The system being a third party application, further optimization or parallel processing was not an option. Hence, we decided to build the compliance rules processing engine outside the database space using the cloud computing platform where performance could be optimized using various techniques including parallel processing. The challenge was that it required data to be transferred from more than 50 database tables to the compliance engine in a real-time manner. It was important to capture all database table events (inserts, updates, and deletes) in a reliable manner and process them in the same sequence as they occurred.
In addition to capturing the database events, we also had to cache them in memory so that the compliance rules processing engine could process them with minimum latency. The mechanism effectively created real-time replicated copies of database tables in memory along with the indexes. In order to write the business logic in type-safe manner, we generated equivalent class objects corresponding to database tables to hold data in memory.
Mechanism
Event Capture
In order to capture events on database tables, i.e. inserts, updates and deletes on tables, a trigger is set up on each table that needs to be replicated. In the trigger, a JSON string is constructed from the columns that need to be replicated and the JSON is inserted into the “Events” table along with other information including transaction type (insert, update, or delete), automatically generated event id, event time, and event status. A newly inserted event will be in “Pending” status. This approach allows us to create a single Events table to capture events on all tables that need to be replicated.
Note that database updates are usually wrapped in a transaction which means when a transaction is rolled back, the event row inserted in the Events tables is also rolled back.
Event Polling
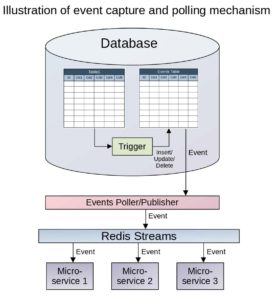
Any process that is interested in capturing the events can poll the Events table at a specific interval for any new events that are inserted in the Events table. To poll the events, we cannot use event id or event time because events do not appear in the Events table sequentially. When multiple transactions are updating the tables, the events appear in the Events table in the order in which the transactions are committed rather than the order in which they are inserted in the Events table.
Hence, for polling the events, event status is used. Selected events are then ordered by event timestamp and can be processed as one event at a time or the batch of events together. Once an event is processed successfully, its status is updated accordingly.
Since the polling of events happens at a specific interval, the replication of data is “semi real-time”. This suffices processing requirements of most of the applications. The polling interval can be reduced to meet specific latency requirements of applications. The main drawback is that the polling can load the database server especially when polled at millisecond intervals, hence it is not suitable for certain types of application that are latency sensitive.
Event Publishing
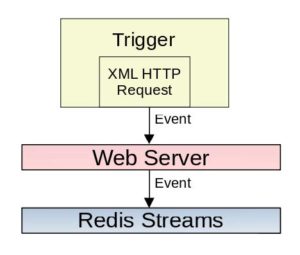
For the applications that need to process events with minimum latency, an event publishing
mechanism is used. In this mechanism, when a database trigger is invoked, an event is published to an external process. The payload for the event is the JSON formatted string that is also written in the Events table.
In order to publish events, i.e. send data to an external process from a stored procedure or a trigger, different database engines offer different mechanisms. One of the mechanisms offered by Microsoft SQL Server is the XML HTTP request. Using this mechanism, an event is sent to a web server which can further distribute it to other processes using message brokers like Kafka, Redis-Streams, etc.
While the publishing mechanism works well, the error handling is tedious. When a database transaction from which a trigger is invoked is rolled back, the published event cannot be unpublished, nor can an additional event be published to indicate cancellation of the previously published event. This requires the event consumer to have a well-orchestrated process to detect the rollback and reverse out the processing of the event. The rollback occurrences can be reduced by pre-validating and updating the database tables in an order such that deadlock does not occur.
Out of Transaction Publishing of Events
Publishing events from a database trigger can fail due to network issues or unavailability of the destination process. In such a case, a re-try is required and it can block the transaction for an undetermined amount of time. To overcome the issue, a loopback mechanism can be developed where the Events table is updated using a loopback interface and a trigger is set on the Events table that would publish the message. Note that the tables updated using loopback interface are not rolled back and care must be taken to detect transaction rollback and reverse the effect of processing of the events generated from the transaction.
Caching Database Tables In Memory
For writing the business logic, a type-safe implementation of objects is used because it not only captures errors at compile time but also provides better performance compared to generic implementation. For each database table, a class object is generated. For storing database rows and implementing indexes in memory, collection classes provided natively by Python and C++ are used.
When an event is received (either by polling or by publishing), its transaction type is examined and based on whether it is inserted, updated, or deleted, the in-memory collections are updated
accordingly.
Code Generator
For replicating a large number of tables using the mechanism, a custom code generator is used. The entire mechanism for replicating database tables in memory was generated using a code generator. The approach provided us with the capability to replicate additional tables by simply specifying which tables and columns to replicate.
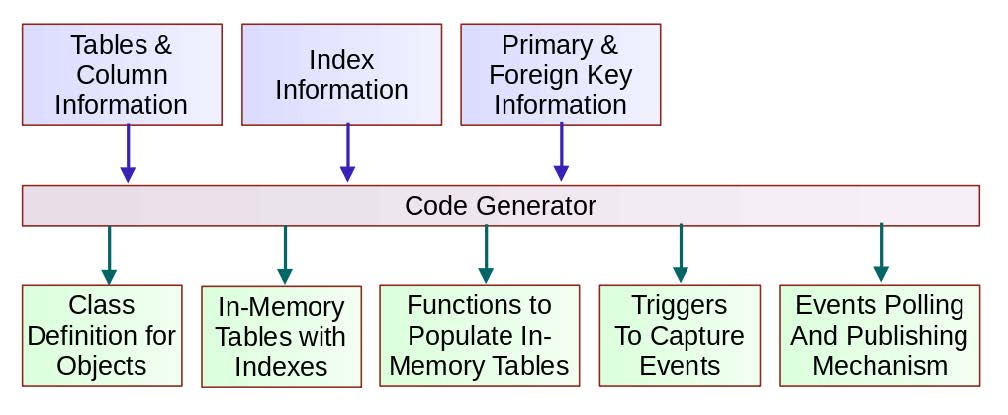
Inputs to code generator
- List of tables and columns to replicate. Column data types and nullability information is automatically extracted from meta data available in the database
- List of indexes to add on the in-memory tables. By default, all indexes present in the database are automatically added.
- Information about primary and foreign keys
Output of the code generator
- Class definitions for objects corresponding to tables that are cached.
- Class interface available in Python, Cython, and C++.
- Class interface for in-memory implementation of tables.
- Indexes are created and updated for all types of transactions.
- Functions to populate in-memory tables
- In-memory tables can be populated from database tables, CSV files or JSON.
- Events capture mechanism
- Triggers are setup on tables to capture events corresponding to insert, update, and delete transactions
- Events polling and publishing mechanism
- Functions to poll for the events, update in-memory tables, and publish events to message broker (Redis-Streams or Kafka)
Caveats
Triggers: The event capture mechanism is based on triggers setup on database tables. Triggers are intrusive to performance of database updates. When a large number of queries are executed in a quick succession (e.g. bulk update of data), database performance can deteriorate. To handle such scenarios, an option is available in the mechanism to suspend the event capture mechanism and re-cache data after the bulk upload is completed.
Column size limit: The mechanism uses a single Events table to capture events on multiple tables and stores event data in JSON format. Databases have a maximum limit on the column size, for example, SQL server supports columns up to 2GB. If a single query updates a huge number of rows, there is a possibility that the data size may exceed the limit. Care must be taken to review the use case of the mechanism to make sure that a single SQL statement does not impact a large number or rows. This can be done by executing the SQL statement in a loop processing a limited number of rows at a time.
Conclusion
The approach for replicating the database tables into memory of daemon processes works in a reliable and efficient manner. It is an effective way to migrate functionality from a monolithic database based application to a cloud based microservices in a non intrusive manner. This paves way for scaling the applications and improving performance characteristics.
Disclaimer
The views expressed in each blog post are the personal views of each author and do not necessarily reflect the views of KKR. Neither KKR nor the author guarantees the accuracy, adequacy or completeness of information provided in each blog post. No representation or warranty, express or implied, is made or given by or on behalf of KKR, the author or any other person as to the accuracy and completeness or fairness of the information contained in any blog post and no responsibility or liability is accepted for any such information. Nothing contained in each blog post constitutes investment, legal, tax or other advice nor is it to be relied on in making an investment or other decision. Each blog post should not be viewed as a current or past recommendation or a solicitation of an offer to buy or sell any securities or to adopt any investment strategy. The blog posts may contain projections or other forward-looking statements, which are based on beliefs, assumptions and expectations that may change as a result of many possible events or factors. If a change occurs, actual results may vary materially from those expressed in the forward-looking statements. All forward-looking statements speak only as of the date such statements are made, and neither KKR nor each author assumes any duty to update such statements except as required by law.